| Home [EN] | Home [JP] | Publications | Projects |
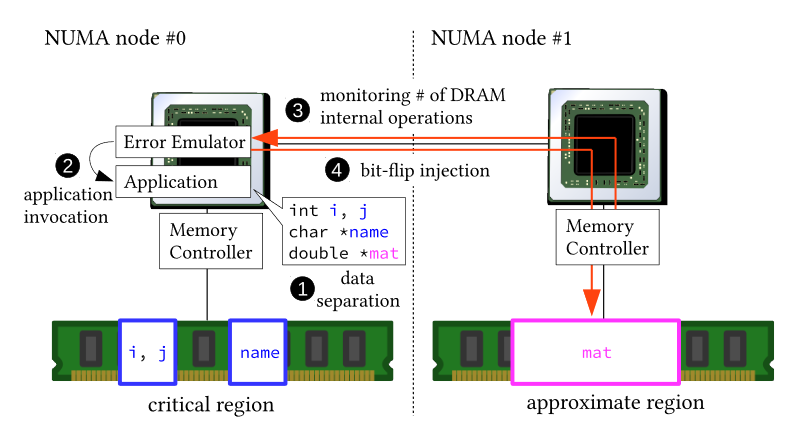
Main memory is the most severe bottleneck both in terms of performance and energy consumption due to its large latency and capacity. Approximate memory enables lower latency and energy consumption to an extent that cannot be achievable with conventional memory, by reducing the timing parameters of DRAM internal operations. Although the relationship between bit-error rates and reduced timing parameters are widely researched in the device level, it is hard to know how approximation affects the output quality of real applications. To this end, we propose a lightweight method to evaluate effect of approximate memory to real applications by counting the number of DRAM internal operations using performance counters. Our system separates approximat-able data and critical data using two NUMA nodes and inject bit-flips only to the former so that the user can specify which data to approximate.
Related Material:
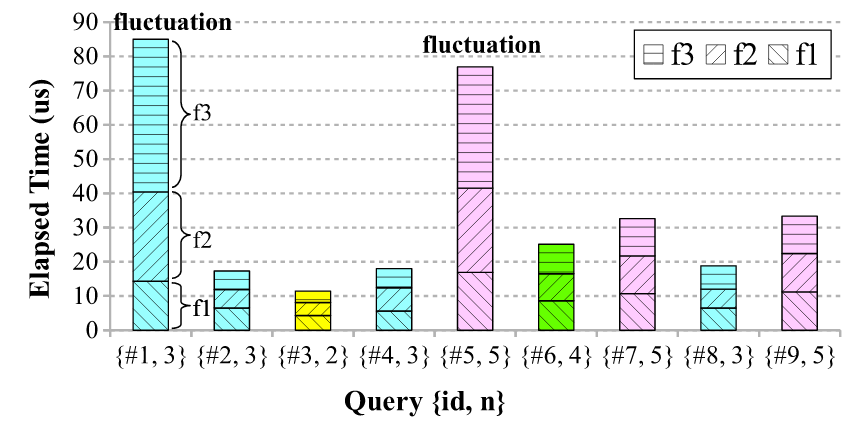
A 'performance fluctuation' refers a phenomenon where the performance (e.g. throughout, latency) of a software system fluctuates for two similar or even identical input data-items (e.g. request, query, packet) due to non-functional states of the software such as cache warmth and resource contention. This is a serious problem because tail latency matters a lot in terms of end user experiences. However, diagnosing (or even observing) a performance fluctuation of high-throughput sotfware is challenging because a data-item stays in a system for a very short period of time and a fluctuation occurs only with specific non-functional states. We leverage Intel PEBS, a fully hardware-based and low-overhead performance monitoring mechanism, to achieve micro-second level estimation of function elapsed time for each data-item for enabling analysis of a single occurrence of a performance fluctuation.
Related Material:
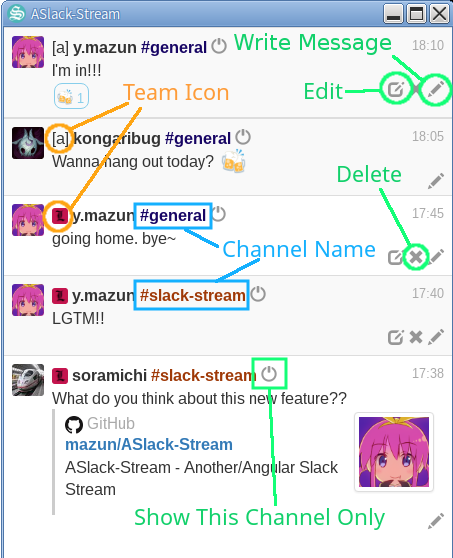
Literally everyone in the IT industry uses Slack nowadays, right? But because everyone uses it, you surely belong to three or four workplaces (FYI: used to be referred to as 'teams'), all of which have a couple of channels. SlackStream, an all-at-a-glance Slack client, can help you a lot. It aggregates all messages from all channels you belong to at one place. You can just keep taking glances to SlackStream, and can go back to the official client once you find something really serious. You no longer need to click the official client lots of times only to look for a small piece of conversations that may not matter.
Related Material:
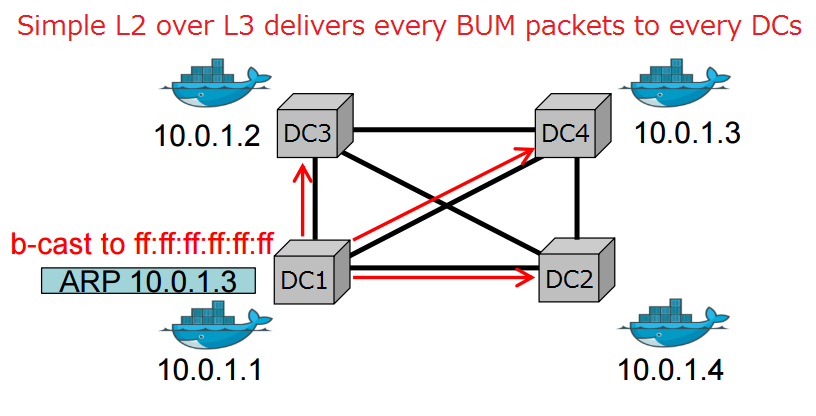
Demand of using Docker is emerging not only in a single host, but also in large slaces such as disaster recovery across multiple DCs and user affinity across multiple continents. However in a large scale setting, deploying a Docker app is not straight forward due to the L3 network boundaries between DCs, and simple L2 overlays do not work as BUM packets are sent to every single DCs. We give a fully open and flexible solution by leveraging EVPN (L2 VPN over L3 network), Open vSwitch, and our yet another BGP daemon, GoBGP.
Related Material:
Live migration mechanism and its use to acheive greener data centers are both actively researched. However, live migration itself has non-negligible energy overhead and it is not properly evaluated in a combination with actual data center operation algorithms. We conducted a large scale simulation to evaluate migration energy overhead with real DC parameters.
Related Material:

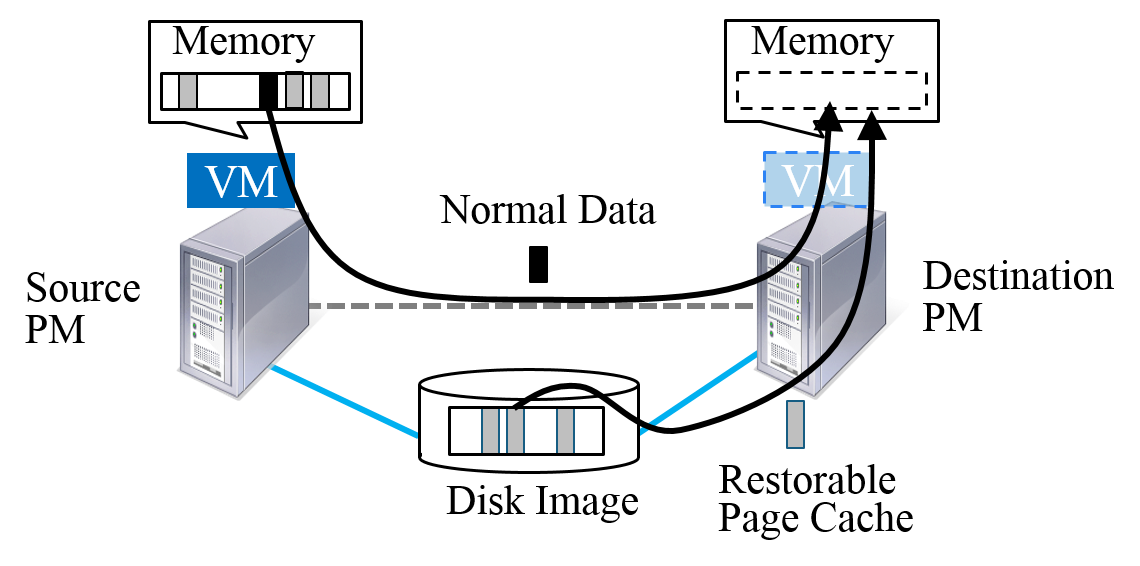
Transferring large amount of VM memory is the biggest challenge of live migration. We found a large portion of VM memory contains page cache (a.k.a. file cache) in common cloud workloads (e.g. web server, database). Page cache teleportation leverages storage area network of the data center to transfer page cache and the other normal data in parallel, to efficiently migrate VMs with large page cache.
Related Material:
Writing high-performance distributed programs become more and more difficult as the number of underlying servers scale. Orleans, a distributed programming framework, frees application programmers from always thinking about complex locking and timing issues by leveragin an actor-based programming model. My internship in Mircrosoft Research was for bottleneck analysis and performance improvement of Orleans, which was further expanded by a latter intern and published in EuroSys 2016.
Related Material:
Live migration is a key technology to dynamically relocate VMs among physhyical hosts to achieve better energy efficiency, memory usage, and load balancing in DCs. We proposed and implemented "memory reusing" technique that transfers only the updated memory pages when a VM migrates back to a host on which the VM has been executed before. The technique significantly acceralates live migration and helps dynamic VM relocation.
Related Material: